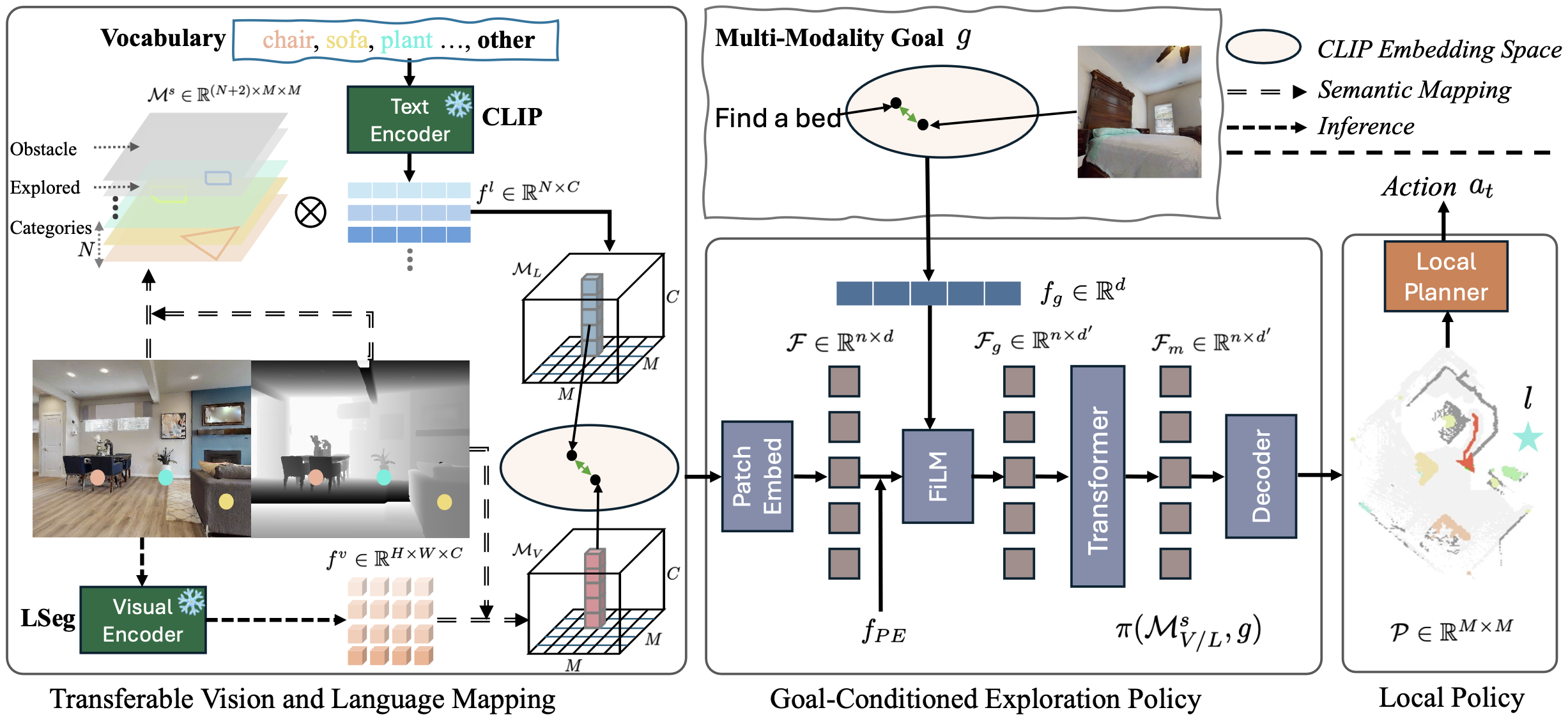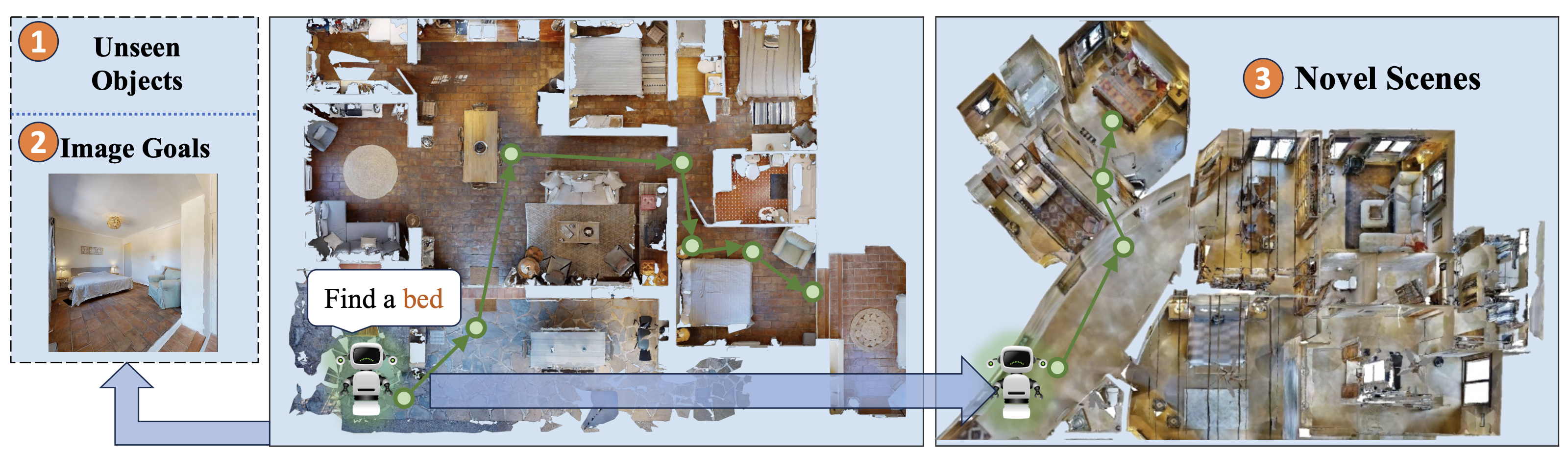
Object-oriented embodied navigation aims to locate specific objects, defined by category or depicted in images. Existing methods often struggle to generalize to open vocabulary goals without extensive training data. While recent advances in Vision-Language Models (VLMs) offer a promising solution by extending object recognition beyond predefined categories, efficient goal-oriented exploration becomes more challenging in an open vocabulary setting. We introduce OVExp, a learning-based framework that integrates VLMs for Open-Vocabulary Exploration. OVExp constructs scene representations by encoding observations with VLMs and projecting them onto top-down maps for goal-conditioned exploration. Goals are encoded in the same VLM feature space, and a lightweight transformer-based decoder predicts target locations while maintaining versatile representation abilities. To address the impracticality of fusing dense pixel embeddings with full 3D scene reconstruction for training, we propose constructing maps using low-cost semantic categories and transforming them into CLIP's embedding space via the text encoder. The simple but effective design of OVExp significantly reduces computational costs and demonstrates strong generalization abilities to various navigation settings. Experiments on established benchmarks show OVExp outperforms previous zero-shot methods, can generalize to diverse scenes, and handle different goal modalities.
@article{wei2024ovexp,
title={OVExp: Open Vocabulary Exploration for Object-Oriented Navigation},
author={Wei, Meng and Wang, Tai and Chen, Yilun and Wang, Hanqing and Pang, Jiangmiao and Liu, Xihui},
journal={arXiv preprint arXiv:2407.09016},
year={2024}
}